
Seit ChatGPT Ende 2022 die Welt der KI-Forschung auf den Kopf gestellt hat, werden täglich dutzende neue und vermeintlich leistungsstarke KI-Modelle veröffentlicht. Als am 20. Jänner das chinesische Forschungslabor DeepSeek sein neuestes Model R1 vorstellte, sorgte dies zuerst für wenig Aufsehen.
Dass das Unternehmen behauptete, R1 wäre gleich performant wie OpenAI’s o1 (das momentan beste kommerziell verfügbare Modell) aber gleichzeitig 97% kostengünstiger, sorgte in Fachkreisen zuerst für Skepsis. Innerhalb weniger Tage wich die Skepsis zunächst Erstaunen und dann Panik. R1 schien zu halten, was es verspricht – und es ist gratis. Damit müssen viele Prämissen des momentanen KI-Booms grundlegend hinterfragt werden.
Hinweis: Die in diesem Beitrag angeführten Unternehmen sind beispielhaft ausgewählt worden und stellen keine Anlageempfehlung dar.
Prämisse 1: bessere Modelle sind teurer
Large Language Models (zu deutsche, große Sprachmodelle, kurz LLMs) sind Vorhersagemodelle, die auf neuronalen Netzwerken beruhen und deren Hauptaufgabe es ist, für einen gegebenen Input, die wahrscheinlichsten nachfolgenden Wortbestandteile (s.g. Tokens) zu liefern. Gebe ich dem Model also den Input „Wenn die Sonne scheint,“ wären wahrscheinliche Outputs „ist“, „der“, „Himmel“, und „blau“ plus einem so genannten End-Token <end>, der dem Model sagt, dass kein weiterer Output folgen soll. Wie und in welcher Reihenfolge die Outputs generiert werden, geben die sogenannten Parameter des Modells vor, die bei der Erstellung des Models „trainiert“ werden müssen.
Vereinfacht gesagt, könnte ein Parameter lauten: „Wenn der vorherige Token <das> lautet, dann ist der nächste Token mit einer Wahrscheinlichkeit von 78% <ist>“. Da die menschliche Sprache aber beinahe unendliche Kombinationsmöglichkeiten von Wörtern und Deutungseinheiten bietet, sind selbst eine Million dieser „wenn-dann“ Regeln nicht ausreichend um einen lesbaren und kohärenten Satz zu bilden.
Brauchbare Modelle starten ab einer Parameter-Dichte von ca. einer Milliarde. Grob gesagt funktioniert ein Model besser, je mehr Parameter es hat. Ein 7-Milliarden-Parameter-Model wie Meta Llama 3.3 (small) kann mühelos auf einem gängigen Laptop installiert werden und liefert gute Antworten für allgemeine Fragen (Wikipedia-Wissen z.B.). Am anderen Ende des Leistungsspektrums stehen Modelle wie OpenAI GPT4o mit einer vermuteten Parameter-Dichte von über einer Billion. Dieses Modell kann Fragen zu speziellen Wissensbereichen wie Medizin oder Maschinenbau mühelos beantworten oder rührselige Gedichte in Armenisch verfassen.
Grundsätzlich gilt, je mehr Parameter das Zielmodel haben soll, desto mehr Rechenoperationen müssen beim Trainieren dieser Modelle aufgebracht werden. Die Basiseinheit für Rechenoperationen nennt man FLOPS (kurz für floating point operations per second). Die Rechenaufgabe 1+1 entspricht einer FLOP. Obwohl in unserem Beispiel GPT4o 170 mal so fähig ist wie das kleine Llama Model, brauchte es 230 mal so viele Rechenressourcen im Training. Kurzum, die Rechenkosten steigen steiler an als die Fähigkeit des Models – zumindest dachte man das bis letzte Woche.
DeepSeek bringt bisherige KI-Modelle unter Druck
Bei der Fülle an Ereignissen darf man eines nicht vergessen: Zwischen dem Trainieren von GPT3, dem ersten Modell mit dem viele von uns Ende 2022 ChatGPT kennenlernten und welches für 10 Millionen US-Dollar trainiert wurde, und der Ankündigung von Präsident Trump für die Weiterentwicklung von KI-Modellen 500 Milliarde US-Dollar bereit zu stellen, sind nur etwas mehr als 2 Jahre vergangen.
In dieser Zeit sind von großen Tech-Unternehmen, Private-Equity-Investoren und Venture-Capitalists schwindelerregende Summen in den KI-Bereich investiert worden. Für 2024 geht man von einer Gesamtsumme von über 300 Mrd. US-Dollar aus. In dieses Umfeld schlug die Nachricht des chinesischen KI-Forschungsteams DeepSeek mit einer Kostenbasis von etwas mehr als 5 Millionen Dollar ein Model trainiert zu haben, das es mit den Spitzenmodellen der US-Techgiganten aufnehmen kann, die dafür das Hundertfache investiert hatten.
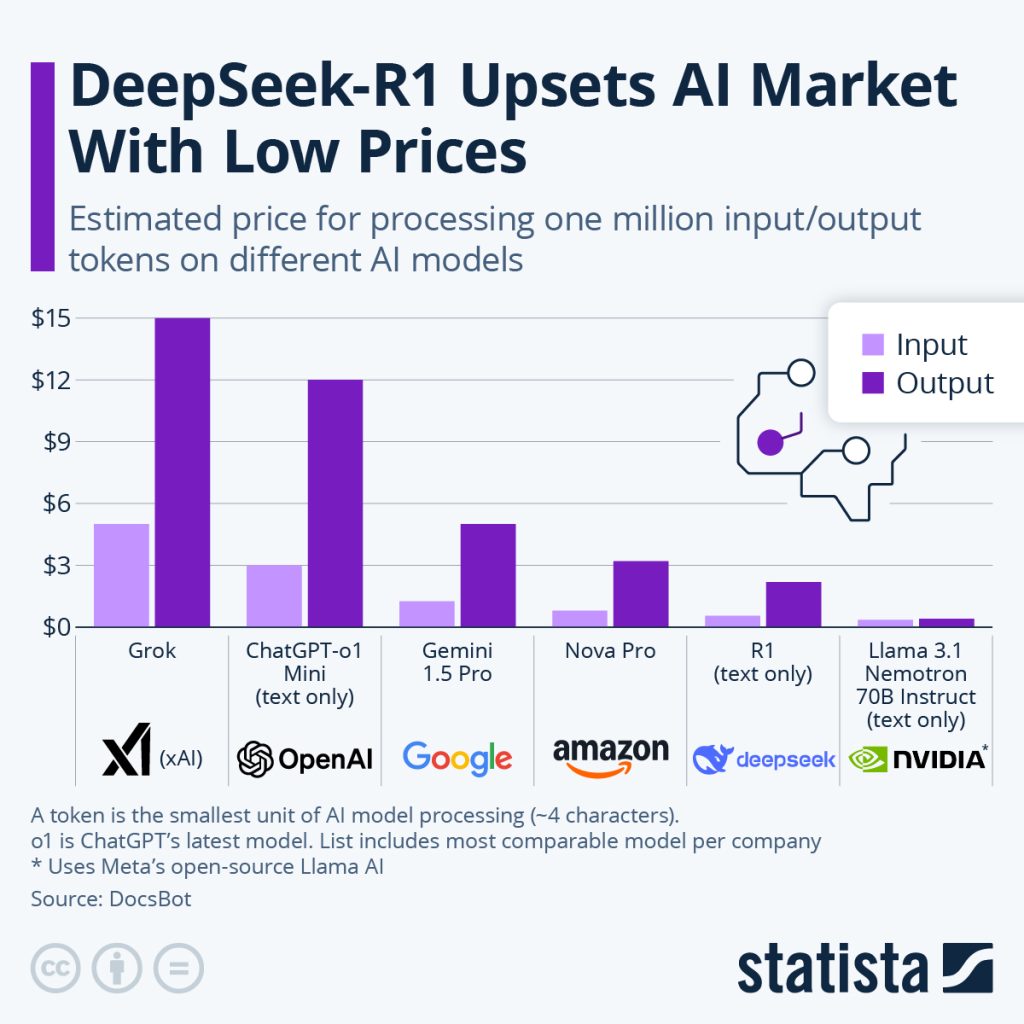
Die Grafik zeigt einen Überblick über die Input- und Outputkosten der gängigsten (und vergleichbaren) KI-Modelle. Quelle: statista.com
Um die Konkurrenzfähigkeit der chinesischen KI-Forschung zu beschränken, hatte bereits die Biden-Regierung Exportverbote für Nvidias neueste Chipgeneration erhoben. Natürlich ist davon auszugehen, dass diese Beschränkungen ähnlich wie bei den Sanktionen gegen Russland über Drittstaatenimporte teilweise umgangen wurden. Fakt ist aber, dass diese Beschränkungen chinesische Forscher dazu brachten, nach ressourcenschonenden Methoden zu suchen, um dieses Handicap zu überwinden.
Das Ergebnis dieser Anstrengungen sind die Modelle DeepSeek V3, R1 und Janus, die jeweils unterschiedliche Anwendungsfälle abbilden. Zum Ungemach der US-Techriesen haben die chinesischen Forscher nicht nur ihre Methoden publiziert, sondern auch ihre Modelle öffentlich zugänglich gemacht. Vereinfacht gesagt, kann sich jeder Anwender mit genug Rechenleistung damit nun sein eigenes ChatGPT erstellen.
Benötigte Rechenleistung könnte massiv einbrechen
Wie die US-Konkurrenz unmittelbar auf diese Entwicklung reagieren wird, ist noch offen. Mittel- bis langfristig ist aber nicht vorstellbar, dass diese bahnbrechenden methodologischen Neuerungen nicht von anderen Forschungsteams übernommen werden. Damit dürfte die benötigte Rechenleistung über die gesamte Industrie hinweg massiv einbrechen. Die Frage drängt sich auf, warum denn nicht einfach die Modelle größer werden, jetzt da die Ressourcen effizienter genutzt werden können.
Ein Auto, das nur 3l/100km braucht, fährt man wesentlich weiter als eines mit einem Verbrauch von 10l/100km, oder? Zum Leidwesen der gesamten Halbleiterindustrie, haben sich in den vergangenen Monaten die Hinweise verdichtet, dass die Leistungsfähigkeit der besten LLM-Modelle einen Plafond erreicht haben und auch mit steigender Parameter-Anzahl keine wesentlich bessere Performance erreicht werden kann.
Prämisse 2: Open-Source ist 2. Liga
In der Software-Distribution unterscheidet man grundsätzlich zwischen Closed-Source und Open-Source. Bei Closed-Source handelt es sich für den Anwender um eine Blackbox, für die nur der Softwarehersteller den Schlüssel hat und damit sehr genau kontrollieren kann, wer die Software wofür nutzt. Open-Source-Software ist ein offenes Buch und frei verfügbar. Jedem Nutzer steht es frei, diese für private oder kommerzielle Zwecke ohne Einschränkungen zu nutzen.
Auch bei KI-Modellen gibt es diese beiden Varianten, wobei die Closed-Variante bis vor einer Woche als die Premium-Variante galt. Zwar stellt der Facebook-Mutterkonzern Meta seine Modelle jedermann zur Verfügung, diese hinken aber in gängigen Benchmarks den kommerziellen Modellen immer ein paar Schritte hinterher. Wer die beste Leistung wollte oder brauchte, musste bisher die Geldbörse öffnen. Damit hat DeepSeek auch Schluss gemacht. Seine Open-Source-Modelle spielen in der ersten Liga mit und sind trotzdem für jeden verfügbar.
Wie könnte sich das auf die Chip-Hersteller auswirken?
Damit wurde über Nacht unzähligen KI-Startups der Gar aus gemacht, die natürlich primär eigene Modelle mit Closed-Source-Distribution bauen müssen, um für ihre Investoren irgendwann Umsätze generieren zu können. Dies hat einerseits zur Folge, dass mittelfristig sehr viele Venture-Investments in diesem Bereich abgeschrieben werden müssen. Nachdem Private-Equity-Fonds sich mit der Abschreibung und dem Reporting in der Regel mehr Flexibilität einräumen können, werden die negativen Folgen dieser Entwicklung mehrere Jahre brauchen, um bei den Investoren zu Buche zu schlagen.
Andererseits besteht die Sorge, dass strauchelnde oder pivotierende Startups im größeren Stil Grafikchips verkaufen werden, die sie über die letzten Jahre teuer mit Investorengeldern angeschafft hatten. Diese Schwemme am Sekundärmarkt könnte die Nachfrage am Primärmarkt ins Wanken bringen. Ein Nvidia H100 Chip aus dem Jahr 2022 kostete beim Launch 30.000 US-Dollar und damit 500 US-Dollar/TFLOP. Der für 2025 angekündigte B100 Chip wird mit 40.000 Dollar gelistet und kostet daher 300 Dollar/TFLOP. Würde der Gebrauchtpreis für die H100 Chips unter die 18.000-Dollar-Marke fallen und eine signifikante Menge verfügbar werden, würden die unit economics (Umsatz und Kosten auf Basis einer einzelnen Einheit, zB. eines Produkts oder einer Dienstleistung) wohl starken Druck auf die Umsätze von Nvidia auszuüben beginnen.
Als Gegenargument könnte man anführen, dass sich durch die effiziente Open-Source-Architektur viele Unternehmen entschließen könnten, ihre eigenen LLMs zu hosten, während sie in der Vergangenheit auf die Cloud-basierten Lösungen der Hyperscaler Amazon, Microsoft und Google zurückgegriffen hätten. So wäre es für ein Unternehmen wie die Erste Group nicht realistisch gewesen einen eigenen Rechencluster für ein LLM zu provisionieren. Um Llama 3.3 Large zu hosten bräuchte man ca. 200 A100 Chips. Neben den 6 Millionen US-Dollar Anschaffungskosten würden sich noch Energie- und Infrastrukturkosten auftürmen, die jegliche Diskussion über ein Selbsthosting beenden würde. DeepSeek R1 wäre nicht nur das bessere Modell, sondern käme auch mit 5-10 A100 Chips aus. Bei 200.000 Dollar Anschaffungskosten könnte das ein oder andere mittelgroße Unternehmen versucht sein, ein Projekt zu starten, um sich selbst an der neuen Technologie zu versuchen und gleichzeitig die Hoheit über die verwendeten Daten zu behalten.
Aus Sicht von Nvidia wäre dieser Schwenk nur zu begrüßen, würde es doch die Abhängigkeit von wenigen großen Kunden mit entsprechender Verhandlungsmacht auf viele kleinere und weniger verhandlungsstarke Kunden verteilen.
Prämisse 3: KI-Modelle sind ein Softwareprodukt
Bis vor kurzem lautete der Business Case der meisten KI-Startups wohl so: „Wir trainieren ein Modell mit Investorengeldern und verdienen dann mit Konsumenten über ein Abo-Modell und mit Unternehmen mit einem API-Modell“. Dieser Annahme lag zugrunde, dass ein KI-Modell ein Produkt ähnlich einer Software wie Office oder Photoshop ist und wenn das eigene Modell nur gut genug ist, wird man die Kunden schon binden können. Am Rande naschten natürlich die US-Techriesen mit, die ihren Obolus für das kosteneffiziente Hosting der API-Modelle forderten. Auch mit diesen Annahmen hat DeepSeek Schluss gemacht. Binnen Tagen kündigten unzählige OpenAI-Kunden ihr Abo und wechselten zur gratis Alternative aus China. Kundenbindung, was ist das?
Hinweis: Prognosen sind kein zuverlässiger Indikator für künftige Wertentwicklungen.
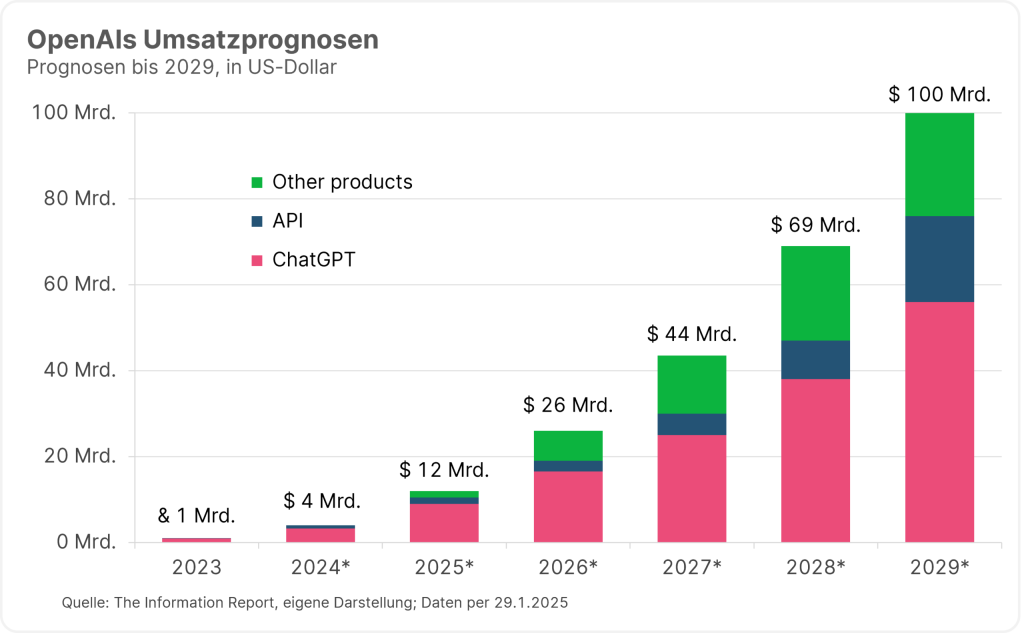
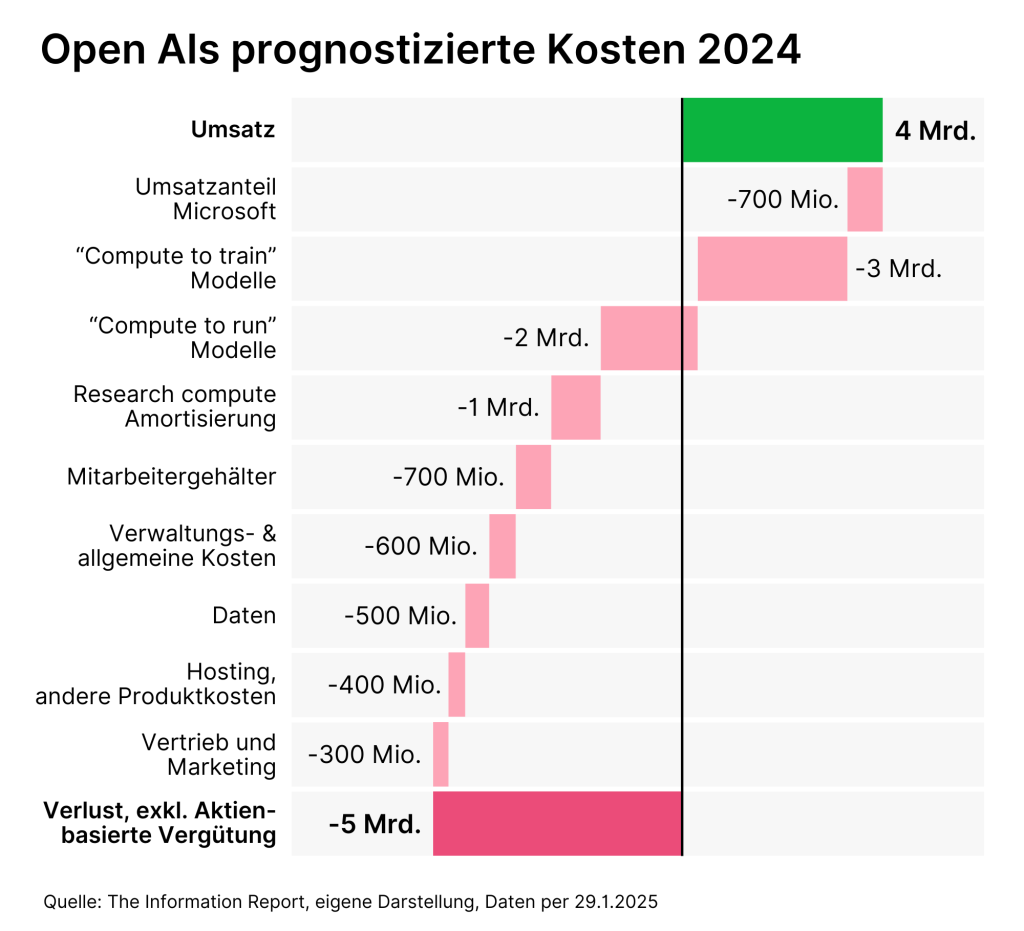
Diese Desillusionierung ist für OpenAI, die Schöpfer von ChatGPT und Wegbereiter des KI-Booms, doppelt schmerzhaft. Einerseits befindet sich das Unternehmen auf dem Weg zum IPO, wo es gerne mehr als 100 Mrd. Dollar an Investorengeldern einsammeln möchte. Hinter diese Absichten muss man nun ein sehr großes Fragezeichen setzen. Andererseits hatte das Unternehmen seine gesamte Wachstumsstrategie auf das B2C-Geschäft gesetzt. Einen Großteil seines Umsatzes von etwa 4 Mrd. US-Dollar im Jahr 2024 kam aus dem Abo-Geschäft. Bis 2029 sollte allein dieser Geschäftszweig auf über 50 Mrd. Dollar anwachsen. Zusätzlich wagte sich OpenAI unlängst in ein neues Preisschema. So sollte das neueste Modell o3 nur mehr Pro-Nutzern zur Verfügung stehen, die bereit sind dafür 200 US-Dollar pro Monat zu zahlen. Damit sollte endlich auch die Rentabilität des Unternehmens stabilisiert werden, das Schätzungen zufolge immer noch für zwei Dollar Umsatz einen Dollar Verlust schreibt.
Die Ankunft von DeepSeek muss daher für OpenAI als existenzielle Bedrohung gesehen werden. Inwieweit der OpenAI-Großinvestor Microsoft dabei Schrammen davonziehen wird, ist noch unklar. Jedenfalls wird das Unternehmen seine Entscheidung hinterfragen müssen, die OpenAI Modelle exklusiv in Microsoft-Copilot-Produktserie integriert zu haben.
Hinweis: Prognosen sind kein zuverlässiger Indikator für künftige Wertentwicklungen.
Regulatorik könnte entscheidende Rolle spielen
Ausgerechnet die vielgeschimpfte Regulatorik könnte den bestehenden Closed-Source-Unternehmen zur Krücke werden. Der EU AI Act und ähnliche Regulatorien fordern weiteichende und komplexe Audits von KI-Modellen, damit diese kommerziell genutzt werden können. Ein relativ kleines Forschungslabor wie DeepSeek, das sein Produkt ohnehin frei zur Verfügung stellt, wird schwer dazu zu bewegen sein, mit seinen Anwälten seitenweise Formulare auszufüllen und nach Brüssel oder Sacramento zu schicken.
Die US-Techriesen sind hier klar im Vorteil und es kann nur eine Frage der Zeit sein, bis die Stimmen laut werden, die eine stärkere Regulierung von Open-Source-Modellen fordern. Teilweise geschieht dies ohnehin schon mit Verweis auf die Selbstzensur von R1, sobald es mit Fragen zu chinesischer Innenpolitik oder Geschichte konfrontiert wird. Ob es dem Durchschnittsanwender wichtig sein wird, dass sein KI-Assistent ihm wahrheitsgemäß über das Massaker am Tiananmen-Platz berichtet, während es für ihn eine Mail an den Chef verfasst, steht auf einem anderen Blatt.
Unausweichlich scheint, dass KI-Modelle künftig als austauschbare Ressource und nicht als Produkt per se angesehen werden. Eine Marktdynamik analog zu den einst hochgefeierten dann rasch standardisierten und rationalisierten Solarpanelen ist denkbar. Dies spielt einerseits Apple und Amazon in die Hände, denen man in den letzten Jahren Untätigkeit im KI-Bereich vorgeworfen hatte. Apple hat es sich zum Ziel gesetzt, KI-Modelle bestmöglich in seine Produkte zu integrieren, ohne sich dabei in eine Ressourcenschlacht ziehen zu lassen. Im Nachhinein betrachtet war dies exakt die richtige Strategie. Amazon hat mit AWS Bedrock den defacto Branchenstandard für das Cloud-Hosting von KI-Modellen geschaffen und sich damit unabhängig vom Erfolg eines einzigen Modellanbieters gemacht.
Investoren werden genau prüfen wer von KI-Implementierung profitiert
Die größte Unsicherheit herrscht momentan im Halbleiterbereich, allen voran natürlich beim Wunderkind Nvidia. Wie oben beschrieben lassen sich momentan wesentlich mehr Argumente für einen Rückgang der Nachfrage nach Grafikprozessoren nennen. In einschlägigen Kreisen wird momentan oft vom so genannten Jevon‘s Paradox gesprochen, das grob besagt, dass sobald eine Softwaredienstleistung günstiger wird, die Nachfrage nach ihr überproportional steigt und den Markt am Ende sogar wachsen lässt. Dem gegenüber steht aber die nach wie vor fehlende „KI Killer App“. Kurzum, würden LLMs und ähnliche Modelle von heute auf morgen verschwinden, würde dies vermutlich nur einer begrenzten Anzahl von Leuten außerhalb der KI-Forschung auffallen.
Für die breite Masse der Nutzer erschöpfen sich die Use Cases für AI am Hausübung schreiben und lustige deepBilder generieren, sofern sie überhaupt die Technologie nutzen. Für Investoren wird es daher umso entscheidender sein, nachzuprüfen welche Unternehmen von der Implementierung von Künstlicher Intelligenz profitieren können und sich nicht in einem unentrinnbaren race-to-the-bottom befinden.
WICHTIGE RECHTLICHE HINWEISE
Hierbei handelt es sich um eine Werbemitteilung. Sofern nicht anders angegeben, Datenquelle Erste Asset Management GmbH. Die Kommunikationssprache der Vertriebsstellen ist Deutsch und jene der Verwaltungsgesellschaft zusätzlich auch Englisch.
Der Prospekt für OGAW-Fonds (sowie dessen allfällige Änderungen) wird entsprechend den Bestimmungen des InvFG 2011 idgF erstellt und veröffentlicht. Für die von der Erste Asset Management GmbH verwalteten Alternative Investment Fonds (AIF) werden entsprechend den Bestimmungen des AIFMG iVm InvFG 2011 „Informationen für Anleger gemäß § 21 AIFMG“ erstellt.
Der Prospekt, die „Informationen für Anleger gemäß § 21 AIFMG“ sowie das Basisinformationsblatt sind in der jeweils aktuell gültigen Fassung auf der Homepage www.erste-am.com jeweils in der Rubrik Pflichtveröffentlichungen abrufbar und stehen dem/der interessierten Anleger:in kostenlos am Sitz der jeweiligen Verwaltungsgesellschaft sowie am Sitz der jeweiligen Depotbank zur Verfügung. Das genaue Datum der jeweils letzten Veröffentlichung des Prospekts, die Sprachen, in denen der Prospekt bzw. die „Informationen für Anleger gemäß § 21 AIFMG“ und das Basisinformationsblatt erhältlich sind, sowie allfällige weitere Abholstellen der Dokumente, sind auf der Homepage www.erste-am.com ersichtlich. Eine Zusammenfassung der Anlegerrechte ist in deutscher und englischer Sprache auf der Homepage www.erste-am.com/investor-rights abrufbar sowie bei der Verwaltungsgesellschaft erhältlich.
Die Verwaltungsgesellschaft kann beschließen, die Vorkehrungen, die sie für den Vertrieb von Anteilscheinen im Ausland getroffen hat, unter Berücksichtigung der regulatorischen Vorgaben wieder aufzuheben.
Hinweis: Sie sind im Begriff, ein Produkt zu erwerben, das schwer zu verstehen sein kann. Bevor Sie eine Anlageentscheidung treffen, empfehlen wir Ihnen, die erwähnten Fondsdokumente zu lesen. Diese Unterlagen erhalten Sie zusätzlich zu den oben angeführten Stellen kostenlos am jeweiligen Sitz der vermittelnden Sparkasse und der Erste Bank der oesterreichischen Sparkassen AG. Sie können die Unterlagen auch elektronisch abrufen unter www.erste-am.com.
Unsere Analysen und Schlussfolgerungen sind genereller Natur und berücksichtigen nicht die individuellen Merkmale unserer Anleger:innen hinsichtlich des Ertrags, der steuerlicher Situation, Erfahrungen und Kenntnisse, des Anlageziels, der finanziellen Verhältnisse, der Verlustfähigkeit oder Risikotoleranz. Die Wertentwicklung der Vergangenheit lässt keine verlässlichen Rückschlüsse auf die zukünftige Entwicklung eines Fonds zu.
Bitte beachten Sie: Eine Veranlagung in Wertpapieren birgt neben den geschilderten Chancen auch Risiken. Der Wert von Anteilen und deren Ertrag können sowohl steigen als auch fallen. Auch Wechselkursänderungen können den Wert einer Anlage sowohl positiv als auch negativ beeinflussen. Es besteht daher die Möglichkeit, dass Sie bei der Rückgabe Ihrer Anteile weniger als den ursprünglich angelegten Betrag zurückerhalten. Personen, die am Erwerb von Investmentfondsanteilen interessiert sind, sollten vor einer etwaigen Investition den/die aktuelle(n) Prospekt(e) bzw. die „Informationen für Anleger gemäß § 21 AIFMG“, insbesondere die darin enthaltenen Risikohinweise, lesen. Ist die Fondswährung eine andere Währung als die Heimatwährung des/der Anleger:in, so können Änderungen des entsprechenden Wechselkurses den Wert der Anlage sowie die Höhe der im Fonds anfallenden Kosten – umgerechnet in die Heimatwährung – positiv oder negativ beeinflussen.
Wir dürfen dieses Finanzprodukt weder direkt noch indirekt natürlichen bzw. juristischen Personen anbieten, verkaufen, weiterverkaufen oder liefern, die ihren Wohnsitz bzw. Unternehmenssitz in einem Land haben, in dem dies gesetzlich verboten ist. Wir dürfen in diesem Fall auch keine Produktinformationen anbieten.
Zu den Beschränkungen des Vertriebs des Fonds an amerikanische oder russische Staatsbürger entnehmen Sie die entsprechenden Hinweise dem Prospekt bzw. den „Informationen für Anleger gemäß § 21 AIFMG“.
In dieser Mitteilung wird ausdrücklich keine Anlageempfehlung erteilt, sondern lediglich die aktuelle Marktmeinung wiedergegeben. Diese Mitteilung ersetzt somit keine Anlageberatung.
Die Unterlage stellt keine Vertriebsaktivität der Verwaltungsgesellschaft dar und darf somit nicht als Angebot zum Erwerb oder Verkauf von Finanz- oder Anlageinstrumenten verstanden werden.
Die Erste Asset Management GmbH ist mit der Erste Bank und den österreichischen Sparkassen verbunden.
Beachten Sie auch die „Informationen über uns und unsere Wertpapierdienstleistungen“ Ihres Bankinstituts.

The Tariff Man
Am vergangenen Sonntag kündigte die US-Regierung neue Zölle für Waren aus Kanada, Mexiko und China an, nur um kurz darauf diese wieder auszusetzen. Wie könnte es im Handelskonflikt weitergehen? Drohen auch der EU neue Zölle?